That is the question I have been looking at for the past 2 weeks. I have been using Airflow for 2 projects since 2018 and I have been mostly happy with it (thanks in part to great colleagues who made it work).
But recently while I was doing research for a new use case I stumbled on a Flyte demo that caught my attention quickly.
The specific feature (a) that drove my interest initially was the dynamic DAG architecture.
I also noticed (b) the tasks and DAGs (“workflows” in Flyte) are real functions (i.e. they have parameters and output) almost like API end-points. Furthermore (c) the tasks can be written as plain Python (alt. Java, Scala) functions. These two design choices intuitively should be making our lives easier.
If at this stage you already want to check Flyte for yourself: https://flyte.org/
Otherwise lets look in more details at the above features.
DAG architectures
The first time I saw an Airflow DAG I thought the concept was great due to its flexibility.
However on a recent project the ideal DAG structure I was looking for was dynamic in the sense it is only at run time of the first task that the number of 2nd level tasks (can run in parallel) is known.
It turns out Flyte covers “Advanced composition” such as:
For my use-case map_tasks are a nice way to parallelize my 2nd level tasks.
Tasks as functions
With regard to this point we should start by acknowledging Airflow DAGs can also have inputs, however that feature is not seamless. On the other hand in Flyte tasks parameters are first class citizen, they are typed with pydantic (this is mandatory for any task definition) and actual types are checked when tasks are triggered. Furthermore Flyte tasks also have output. Both the tasks inputs and outputs can be visualized at each step of a workflow execution.
For example the following screenshot shows a Task taking a list of dates as input: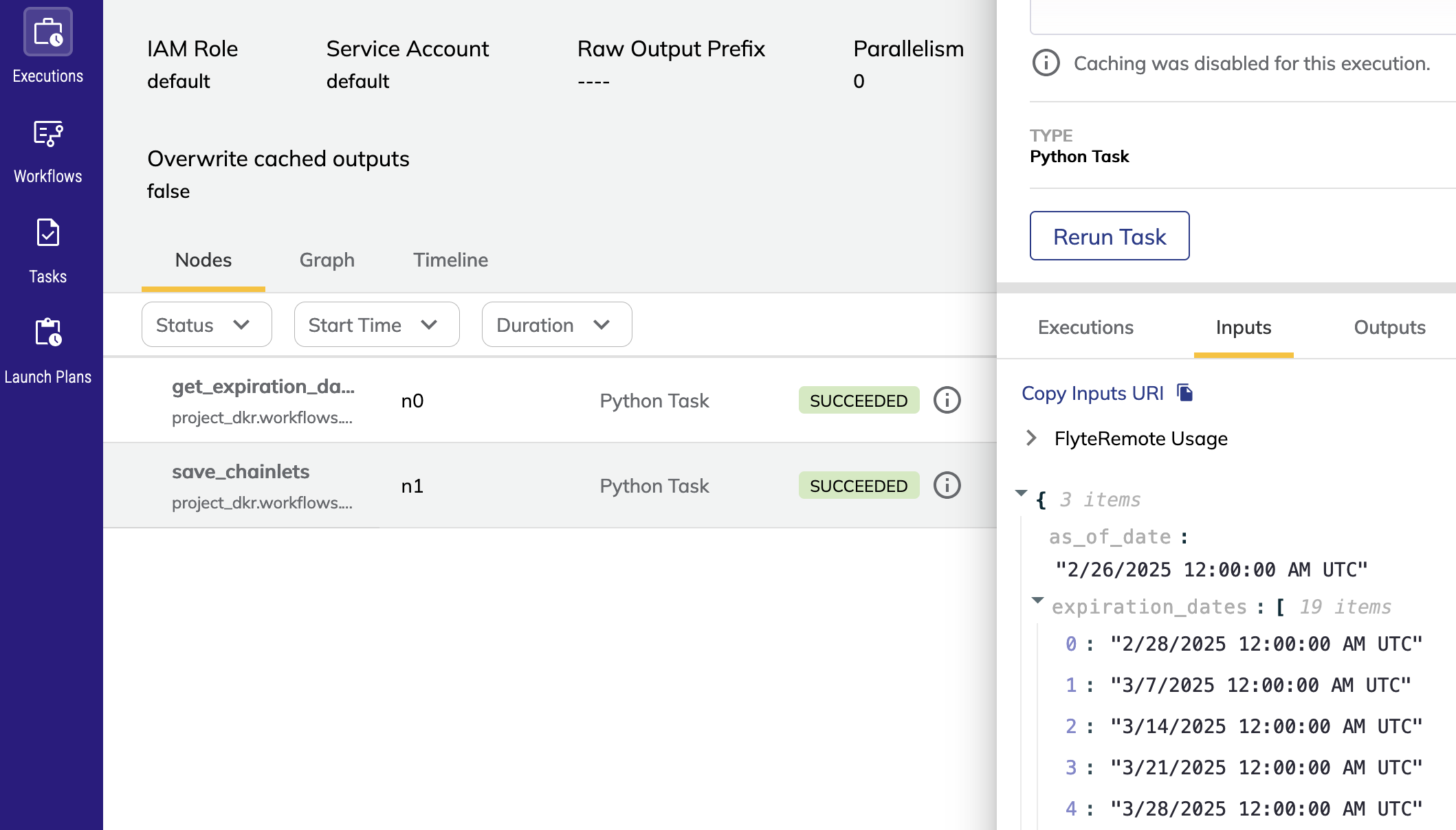
Tasks definition
Plain vanilla code (Python, Scala, Java)
If you are using custom python packages with versioning for each of your DAGs in Airflow it is likely you are creating Docker images and the KubernetesPodOperator to pass down python command are execution string.
So with Airflow code for a Task would look like this (ignoring some operator parameters to focus on the function definiton:
return KubernetesPodOperator(
cmds=["/bin/sh", "-c", f"poetry run python -c '{YOUR_PYTHON_SCRIPT_HERE}'"],
namespace=NAMESPACE,
image=f"{DOCKER_REPO}/{image}",
)
This is quite different from Flyte where you define your task logic in pure python so that you can even run the actualy task locally. It makes the task code iteration process so much more fluid (you can write/test your DAG Task in a Jupyter notebook!). For example quite often the python dependencies you are using dont change for a job, you can simply change the code inside your function and re-register. Flyte will re-used the same Docker image as the dependencies did not change so re-registering your task to the Flyte backend is quick.
Docker command
Some other features similar to Airflow
Above we talked about Task and Workflow. The concept that is closer to Airflow DAG is maybe the LaunchPlan which is a workflow (graph of tasks) with a schedule.
Triggering job execution and tracking their status can be done via the UI or via a scheduler (Flyte LaunchPlan) but there is also the possibility to use the Python client or the gRPC client. Both are quite feature rich and well documented.
Flyte gives a lot of control over the execution pods for a given task, cpu/memory, cpu/gpu, node pool selection.
Events posted on Kafka, GC PubSub, AWS SQS.
Missing feature
Function definition visibility from the UI
DAG concurrency
Key feature that Airflow has but Flyte does not : max concurrent execution for a job. However the Flyte slack chat suggest there is ongoing work for this feature for a few months now so I am hopefull it will be released soon.
DAG execution callbacks
Flyte is able to send Slack or email notification for workflow completion but it lacks a more general callback mechanism. However it generates events and it is possible to configure the backend to post these events GC PubSub or on Kafka topics. So by subscription to these topics we can achieve most of what we need from a callback.
Documentation
The website comes with its own LLM powered chatbot (from Run LLM) based on the knowledge from the website, the code base and the Slack channel.
Screenshots
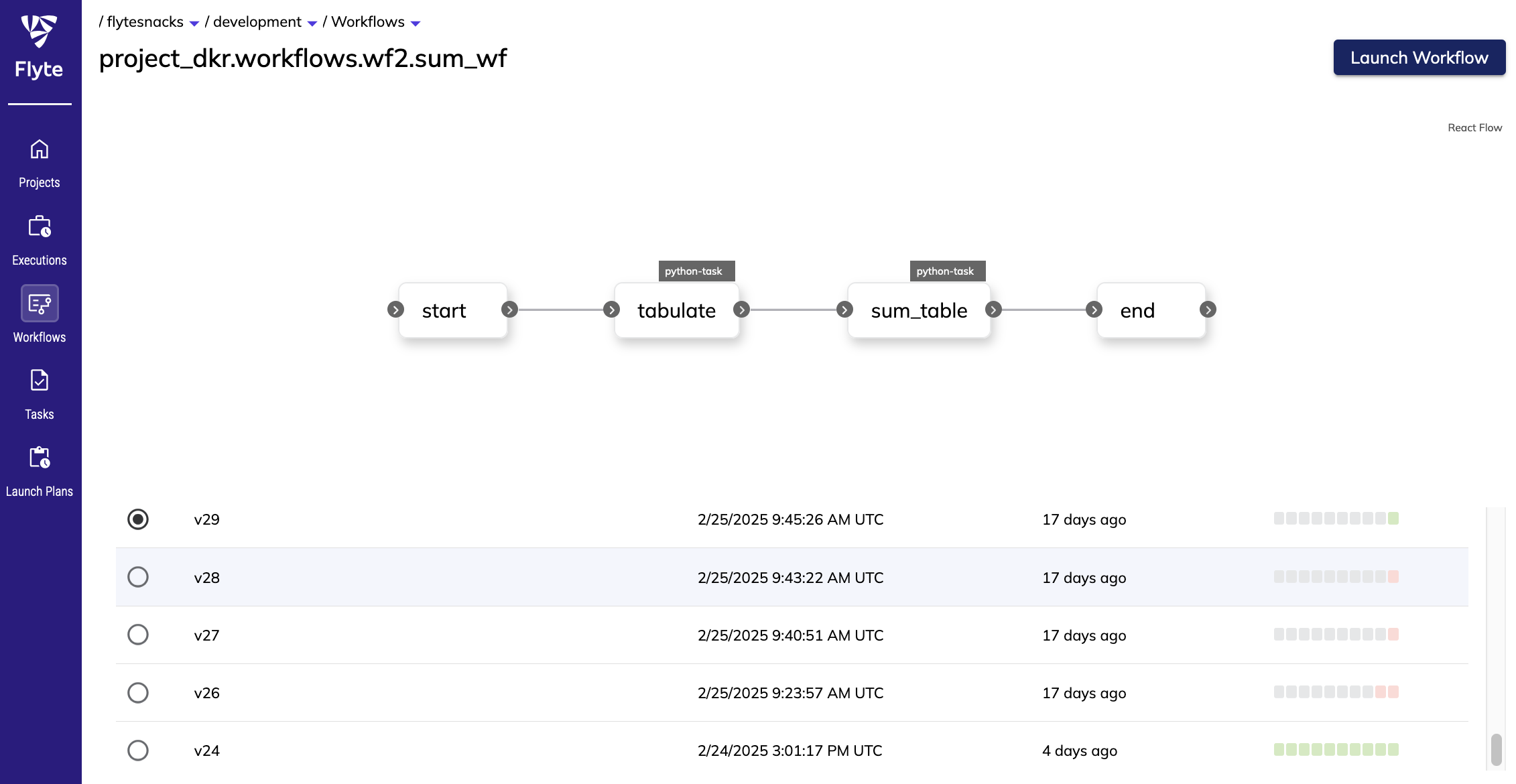
The next screenshot shows worfklows browser. Beside the DAG architecture we can see the list of all the different versions and their last 10 runs.
Selecting a given revision number will show more details such as change in architecture or change in the docker images.
Remark: This way of seeing run success/failure bucketed by revision number can be convenient in production to investigate an issue.